
scikit-learnでクラスタリングしてみる
はじめに
どうもこんにちは。ブログさぼりまくりだったので久しぶりに書きます。
今回はpython用機械学習ライブラリscikit-learnを使ってクラスタリングを行ってみたいと思います。環境はMac OSX Elcapitanでpythonのバージョンは3.5です。
クラスタリングの詳解は省きますが、教師なし学習の一種でデータを指定されたクラスタ数に分け、データの特性を把握することを目的とします。
今回は基本であるk平均法を使ってクラスタリングを行います。k平均法は、いくつかのクラスタの重心を決めて各特徴ベクトルを最も近い重心のクラスタに割り振ります。その後、各クラスタに割り当てられたベクトルの平均値に重心を移動させ、再度クラスタを割り振るという2段階のステップを繰り返し最終的に収束したクラスタを結果として返します。
クラスタリングするデータにはとあるSNSにおけるスポット(位置・物件情報)データを用意しました。クリップ数、掲載写真数、ユーザー投稿数などが紐付いています。
実装
構成はこんな感じになっています。
各ファイルについて
各ファイルを簡単に解説してみます。
requirements.txt
必要となるライブラリの一覧。pythonはpipというパッケージ管理システムでライブラリを管理するのが一般的です。Rubyで言えばgemです。
以下のコマンドでインストールしてある一覧を出力することができます。
$ pip freeze
requirements.txtはRuby(Bundler)で言えばGemfileのようなものです、名前は決まっているわけではないですが慣例的にこの名前が使われます。以下のようにインストール済みリストを出力できます。
$ pip freeze -l > requirements.txt
今回使っているライブラリは以下のようになっています。
configparser==3.5.0 mysqlclient==1.3.9 scikit-learn==0.17.1 numpy==1.11.1 matplotlib==1.5.2 scipy==0.18.0
requirements.txtを用意しておけば以下のようにして一括インストールすることもできます。
$ pip install -r requirements.txt
init.py
init.pyはpythonファイルのあるディレクトリを表すということと、モジュールインポートなどの初期化処理等を記述できるという役割があります。今回は特に初期化処理等は記述していないので空ファイルです。
db.cnf
db接続情報を記述してあります。
[db] host = localhost port = 3306 user = root password = database = clustering_test charset = utf8
db.py
db.cnfを元にDB接続処理を記述してあります。use_unicode=1を入れておかないと文字化けする事があるかもしれません。
# -*- coding:utf-8 -*-
import MySQLdb
import configparser
config = configparser.ConfigParser()
config.read('config/db.cnf')
dbhandle = MySQLdb.connect(
host = config.get('db', 'host'),
port = config.getint("db","port"),
user = config.get('db', 'user'),
passwd = config.get('db', 'password'),
db = config.get('db', 'database'),
charset = config.get('db', 'charset'),
use_unicode=1
)
con = dbhandle.cursor(MySQLdb.cursors.DictCursor)
spot.py
spotクラスです。主にspotデータを取得してきます。
# -*- coding:utf-8 -*-
import app.models.db as db
class Spot:
def load_data(self):
sql = "SELECT * from spots" # スポットのデータを取得
db.con.execute(sql)
data = db.con.fetchall()
# クリップ、掲載写真数、投稿数の順にlistで返却
return [[d["clip"], d["image_count"], d["photo_count"]] for d in data]
clustering_plot3d.py
3Dグラフを描画します。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
import app.models.spot as sp
# matplotlibのグラフを用意
fig = plt.figure(1, figsize=(12, 9))
# グラフの初期化
plt.clf()
# matplotlibの3次元グラフ
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
# 軸の初期化
plt.cla()
# DBからspotsレコードを取得しnumpy配列に変換
spot = sp.Spot()
spots = np.array(spot.load_data())
# k平均法でクラスタリング(クラスタ数3)
# random_stateはクラスタ重心のランダマイズのための適当な数値
est = KMeans(n_clusters=3, random_state=150)
est.fit(spots)
# クラスタリング結果のラベル配列
labels = est.labels_
# 散布図を作成。X軸,Y軸,Z軸とcolorを指定
# spots[:, x]はspots行列のx列目を配列で取得
ax.scatter(spots[:, 1], spots[:, 2], spots[:, 0], c=labels.astype(np.float))
# 各軸のラベル付け
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('image_count')
ax.set_ylabel('photo_count')
ax.set_zlabel('clip')
# グラフの描画
plt.show()
以下のコマンドを実行するとグラフが描画されます。
$ python clustering_plot3d.py
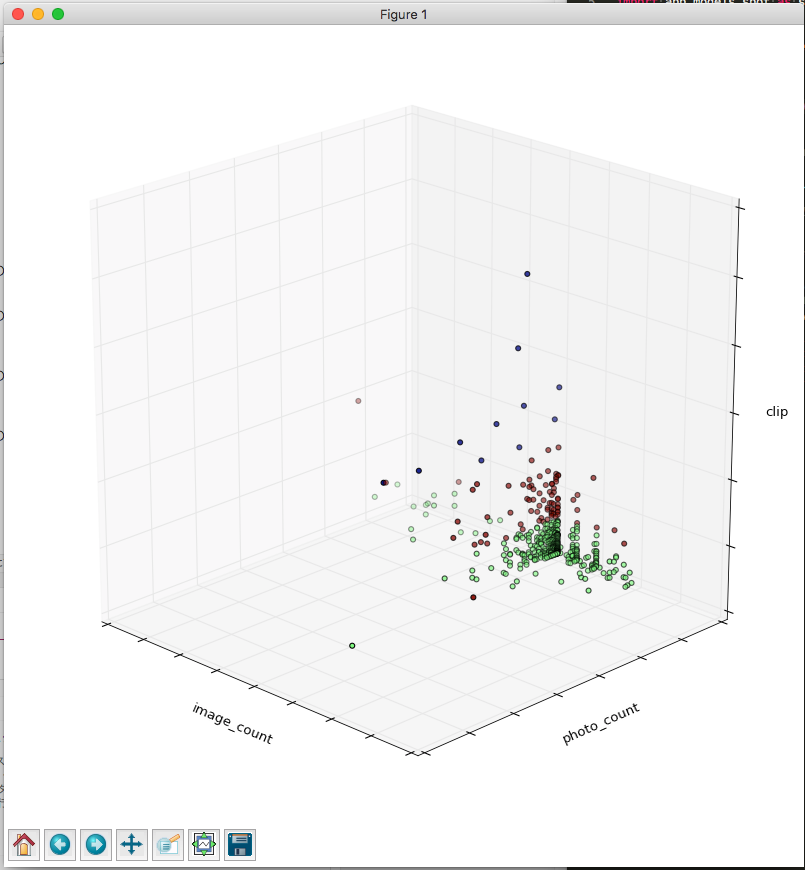
グリグリ動きます。
clustering_plot2d.py
2Dグラフを描画します。今回は3つ組み合わせがあるので3つ描画してみます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import app.models.spot as sp
# グラフを用意
plt.figure(figsize=(10, 10))
# DBからspotsのデータを取得
spot = sp.Spot()
spots = np.array(spot.load_data())
# クラスタ数3でクラスタリング
y_pred = KMeans(n_clusters=3, random_state=170).fit_predict(spots)
# x軸とy軸の組み合わせ別に3つのグラフをプロットする
plt.subplot(221)
plt.scatter(spots[:, 0], spots[:, 2], c=y_pred)
plt.title("clip x photo_count")
plt.subplot(222)
plt.scatter(spots[:, 0], spots[:, 1], c=y_pred)
plt.title("clip x image_count")
plt.subplot(223)
plt.scatter(spots[:, 1], spots[:, 2], c=y_pred)
plt.title("image_count x photo_count")
# グラフ描画
plt.show()
実行すると以下のグラフが描画されます。
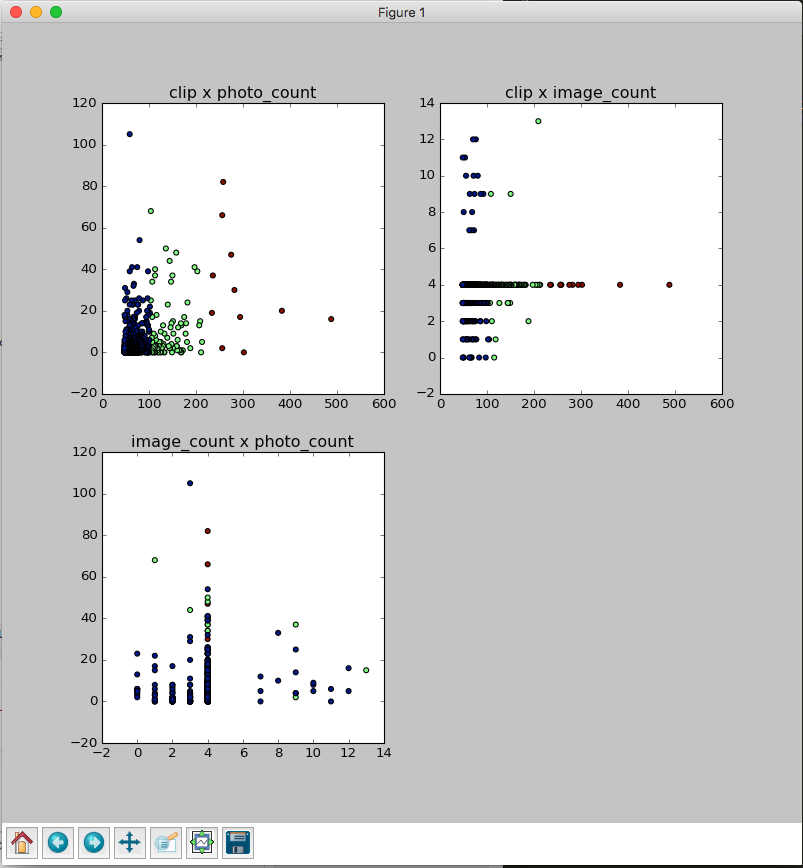
おわりに
という感じで実際のクラスタリング部分はわずか一行で実装出来てしまいました。
今回はクリップ数、掲載写真数、投稿数の3つのみを使いましたが、他にフィーチャーを増やしたりすることでより良くデータの特性を把握できるようになると思います。
今後も継続していきたいと思います。
TAG

基本的にRuby on Railsで開発してます。最近はvue.jsも。好きな塔は円城です。




TAG
- Android
- AWS
- Bitrise
- CodePipeline
- Firebase
- HTML
- iOS
- IoT
- JavaScript
- KPI
- Linux
- Mac
- Memcached
- MGRe
- MGReのゆるガチエンジニアブログ
- MySQL
- PHP
- PICK UP
- PR
- Python
- Ruby
- Ruby on Rails
- SEO
- Swift
- TIPS
- UI/UX
- VirtualBox
- Wantedly
- Windows
- アクセス解析
- イベントレポート
- エンジニアブログ
- ガジェット
- カスタマーサクセス
- サーバ技術
- サービス
- セキュリティ
- セミナー・展示会
- テクノロジー
- デザイン
- プレスリリース
- マーケティング施策
- マネジメント
- ラボ
- リーンスタートアップ
- 企画
- 会社紹介
- 会社紹介資料
- 勉強会
- 実績紹介
- 拡張性
- 採用
- 日常
- 書籍紹介
- 歓迎会
- 社内イベント
- 社員インタビュー
- 社長ブログ
- 視察
- 開発環境